Module 1 An introduction to RL
This module gives a short introduction to Reinforcement learning.
1.1 Learning outcomes
By the end of this module, you are expected to:
- Describe what RL is.
- Be able to identify different sequential decision problems.
- Know what Business Analytics are and identify RL in that framework.
- Memorise different names for RL and how it fits in a Machine Learning framework.
- Formulate the blocks of a RL model (environment, agent, data, states, actions, rewards and policies).
- Run your first RL algorithm and evaluate on its solution.
The learning outcomes relate to the overall learning goals number 3, 5, 6, 9 and 11 of the course.
1.2 Textbook readings
For this week, you will need to read Chapter 1-1.5 in Sutton and Barto (2018). Read it before continuing this module.
1.3 What is reinforcement learning
RL can be seen as
- An approach of modelling sequential decision making problems.
- An approach for learning good decision making under uncertainty from experience.
- Mathematical models for learning-based decision making.
- Trying to optimize decisions in a sequential decision model. That is, making a good sequence of decisions.
- Estimating and finding near optimal decisions of a stochastic process with sequential decision making.
- A model where given a state of a system, the agent wants to take actions to maximize future reward. Often the agent does not know the underlying setting and, thus, is bound to learn from experience.
Sequential decision problems are problems where you take decisions/actions over time. As an agent, you base your decision on the current state of the system (a state is a function of the information/data available). At the next time-step, the system have moved (stochastically) to the next stage. Here new information may be available and you receive a reward and take a new action. Examples of sequential decision problems are (with possible actions):
- Playing backgammon (how to move the checkers).
- Driving a car (left, right, forward, back, break, stop, …).
- How to invest/maintain a portfolio of stocks (buy, sell, amount).
- Control an inventory (wait, buy, amount).
- Vehicle routing (routes).
- Maintain a spare-part (wait, maintain).
- Robot operations (sort, move, …)
- Dairy cow treatment/replacement (treat, replace, …)
- Recommender systems e.g. Netflix recommendations (videos)
Since RL involves a scalar reward signal, the goal is to choose actions such that the total reward is maximized. Note actions have an impact on the future and may have long term consequences. As such, you cannot simply choose the action that maximize the current reward. It may, in fact, be better to sacrifice immediate reward to gain more long term reward.
RL can be seen as a way of modelling intuition. An RL model has specific states, actions and reward structure and our goal as an agent is to find good decisions/actions that maximize the total reward. The agent learn using, for instance:
- totally random trials (in the start),
- sophisticated tactics and superhuman skills (in the end).
That is, as the agent learn, the reward estimate of a given action becomes better.
As humans, we often learn by trial and error too:
- Learning to walk (by falling/pain).
- Learning to play (strategy is based on the game rules and what we have experienced works based on previous plays).
This can also be seen as learning the reward of our actions.
1.4 RL and Business Analytics
Business Analytics (BA) (or just Analytics) refers to the scientific process of transforming data into insight for making better decisions in business. BA can both be seen as the complete decision making process for solving a business problem or as a set of methodologies that enable the creation of business value. As a process it can be characterized by descriptive, predictive, and prescriptive model building using “big” data sources.
Descriptive Analytics: A set of technologies and processes that use data to understand and analyze business performance. Descriptive analytics are the most commonly used and most well understood type of analytics. Descriptive analytics categorizes, characterizes, consolidates, and classifies data. Examples are standard reporting and dashboards (KPIs, what happened or is happening now?) and ad-hoc reporting (how many/often?). Descriptive analytics often serves as a first step in the successful application of predictive or prescriptive analytics.
Predictive Analytics: The use of data and statistical techniques to make predictions about future outputs/outcomes, identify patterns or opportunities for business performance. Examples of techniques are data mining (what data is correlated with other data?), pattern recognition and alerts (when should I take action to correct/adjust a spare part?), Monte-Carlo simulation (what could happen?), neural networks (which customer group are best?) and forecasting (what if these trends continue?).
Prescriptive Analytics: The use of optimization and other decision modelling techniques using the results of descriptive and predictive analytics to suggest decision options with the goal of improving business performance. Prescriptive analytics attempt to quantify the effect of future decisions in order to advise on possible outcomes before the decisions are actually made. Prescriptive analytics predicts not only what will happen, but also why it will happen and provides recommendations regarding actions that will take advantage of the predictions. Prescriptive analytics are relatively complex to administer, and most companies are not yet using it in their daily course of business. However, when implemented correctly, it can have a huge impact on business performance and how businesses make decisions. Examples on prescriptive analytics are optimization in production planning and scheduling, inventory management, the supply chain and transportation planning. Since RL focus optimizing decisions it is Prescriptive Analytics also known as sequential decision analytics.
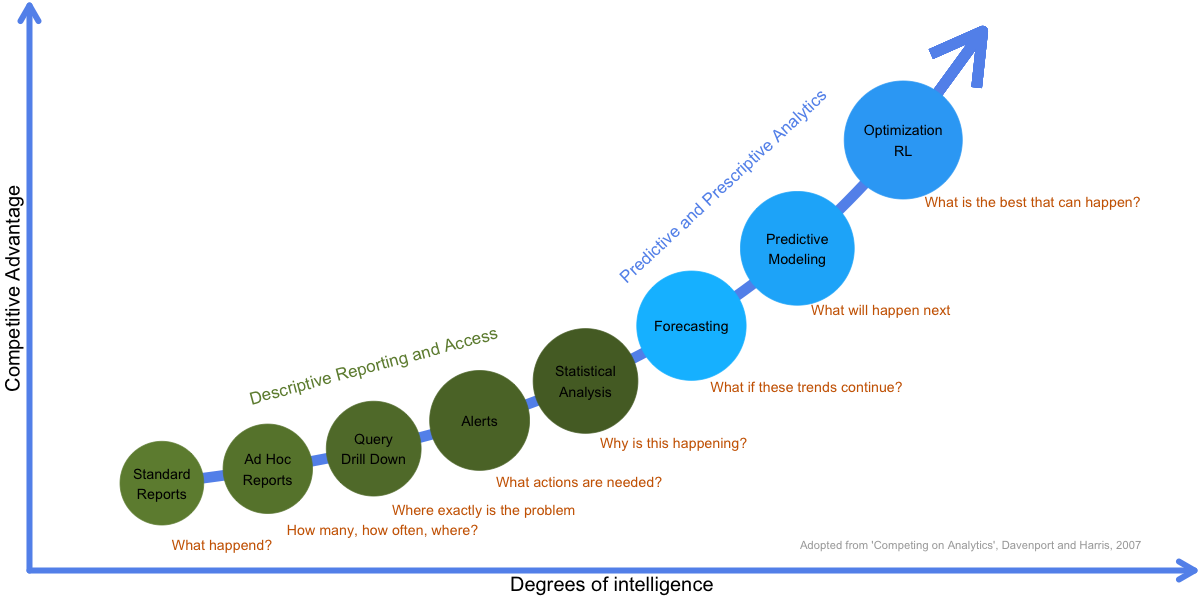
Figure 1.1: Business Analytics and competive advantage.
Companies who use BA focus on fact-based management to drive decision making and treats data and information as a strategic asset that is shared within the company. This enterprise approach generates a companywide respect for applying descriptive, predictive and prescriptive analytics in areas such as supply chain, marketing and human resources. Focusing on BA gives a company a competive advantage (see Figure 1.1).
BA and related areas: In the past Business Intelligence traditionally focuses on querying, reporting, online analytical processing, i.e. descriptive analytics. However, a more modern definition of Business Intelligence is the union of descriptive and predictive analytics. Operations Research or Management Science deals with the application of advanced analytical methods to help make better decisions and can hence be seen as prescriptive analytics. However, traditionally it has been taking a more theoretical approach and focusing on problem-driven research while BA takes a more data-driven approach. Logistics is a cross-functional area focusing on the effective and efficient flows of goods and services, and the related flows of information and cash. Supply Chain Management adds a process-oriented and cross-company perspective. Both can be seen as prescriptive analytics with a more problem-driven research focus. Advanced Analytics is often used as a classification of both predictive and prescriptive analytics. Data science is an interdisciplinary field about scientific methods, processes, and systems to extract knowledge or insights from data in various forms, either structured or unstructured and can be seen as Business analytics applied to a wider range of data.
1.5 RL in different research deciplines
RL is used in many research fields using different names:
- RL (most used) originated from computer science and AI.
- Approximate dynamic programming (ADP) is mostly used within operations research.
- Neuro-dynamic programming (when states are represented using a neural network).
- RL is closely related to Markov decision processes (a mathematical model for a sequential decision problem).
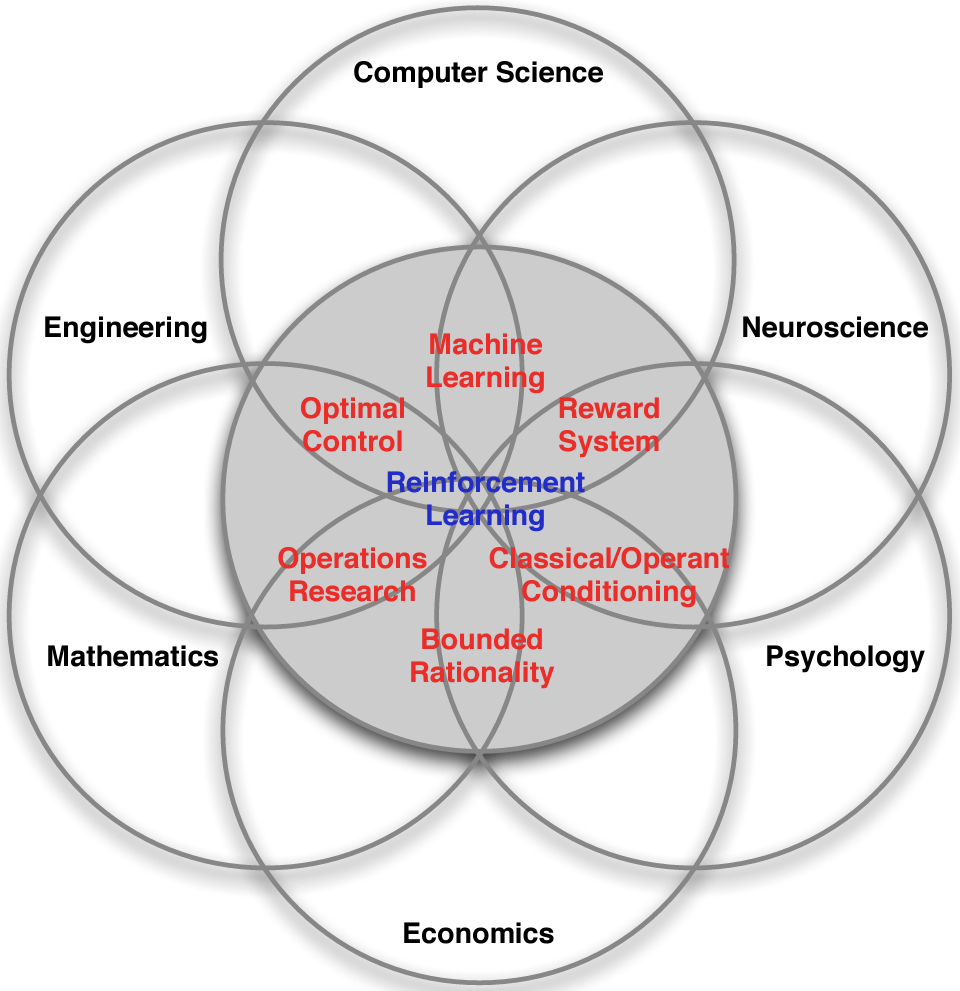
Figure 1.2: Adopted from Silver (2015).
1.6 RL and machine learning
Different ways of learning:
- Supervised learning: Given data \((x_i, y_i)\) learn to predict \(y\) from \(x\), i.e. find \(y \approx f(x)\) (e.g. regression).
- Unsupervised learning: Given data \((x_i)\) learn patterns using \(x\), i.e. find \(f(x)\) (e.g. clustering).
- RL: Given state \(x\) you take an action and observe the reward \(r\) and the new state \(x'\).
- There is no supervisor \(y\), only a reward signal \(r\).
- Your goal is to find a policy that optimize the total reward function.
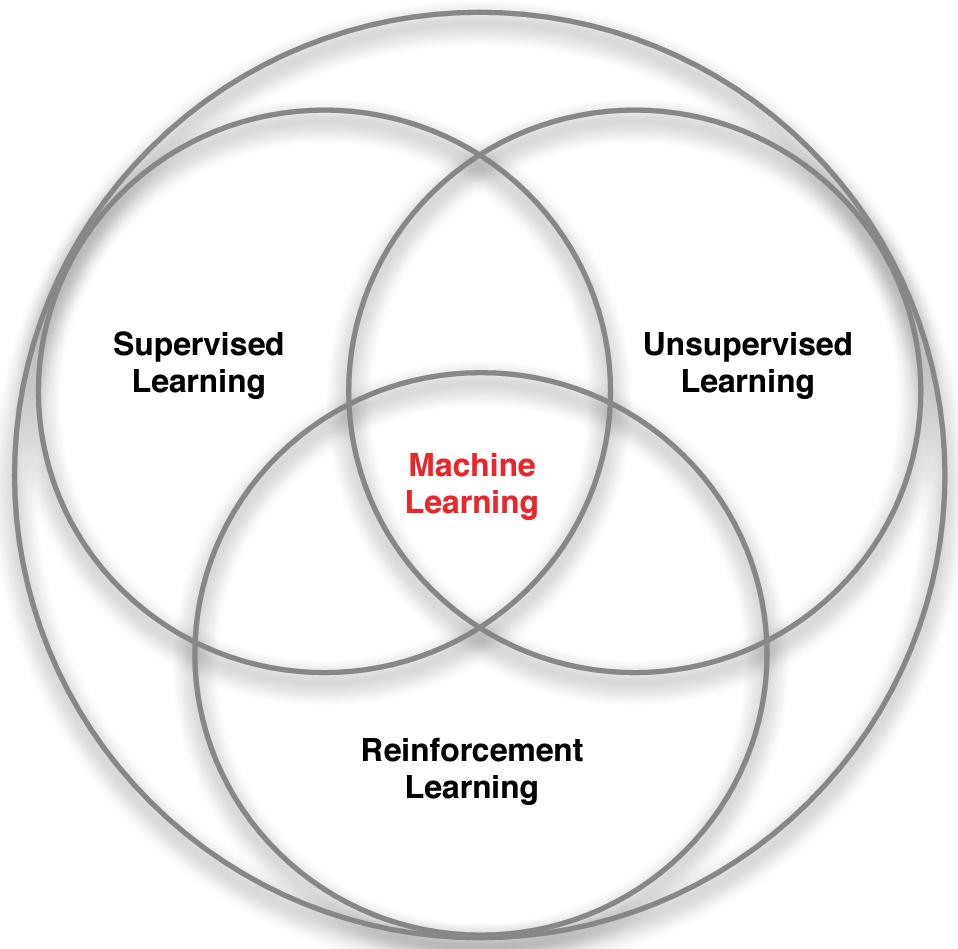
Figure 1.3: Adopted from Silver (2015).
1.7 The RL data-stream
RL considers an agent in an environment:
- Agent: The one who takes the action (computer, robot, decision maker).
- Environment: The system/world where observations and rewards are found.
Data are revealed sequentially as you take actions \[(O_0, A_0, R_1, O_1, A_1, R_2, O_2, \ldots).\] At time \(t\) the agent have been taken action \(A_{t-1}\) and observed observation \(O_t\) and reward \(R_t\):
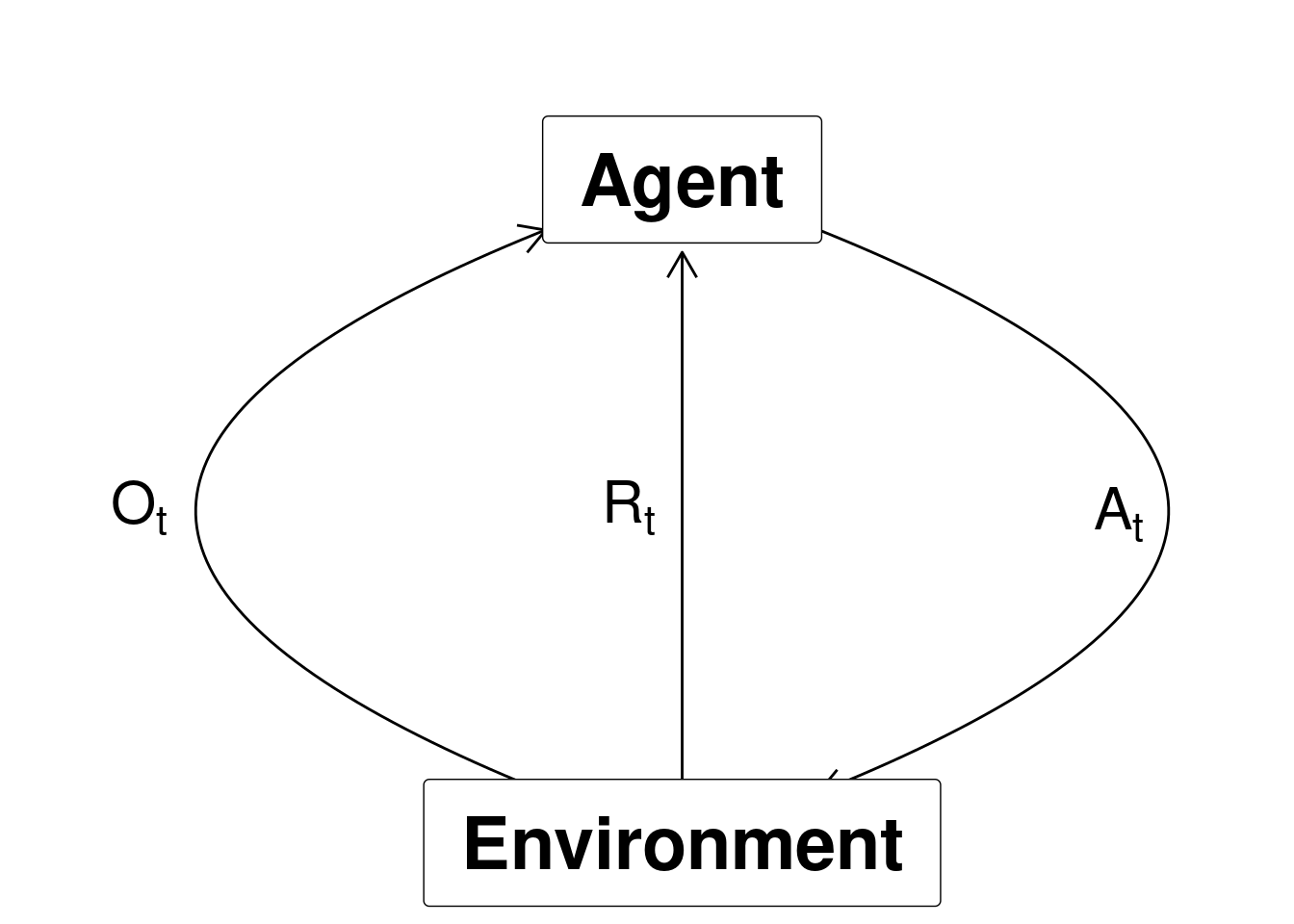
Figure 1.4: Agent-environment representation.
This gives us the history at time \(t\) is the sequence of observations, actions and rewards \[H_t = (O_0, A_0, R_1, O_1, \ldots, A_{t-1}, R_t, O_t).\]
1.8 States, actions, rewards and policies
The (agent) state \(S_t\) is the information used to take the next action \(A_t\):
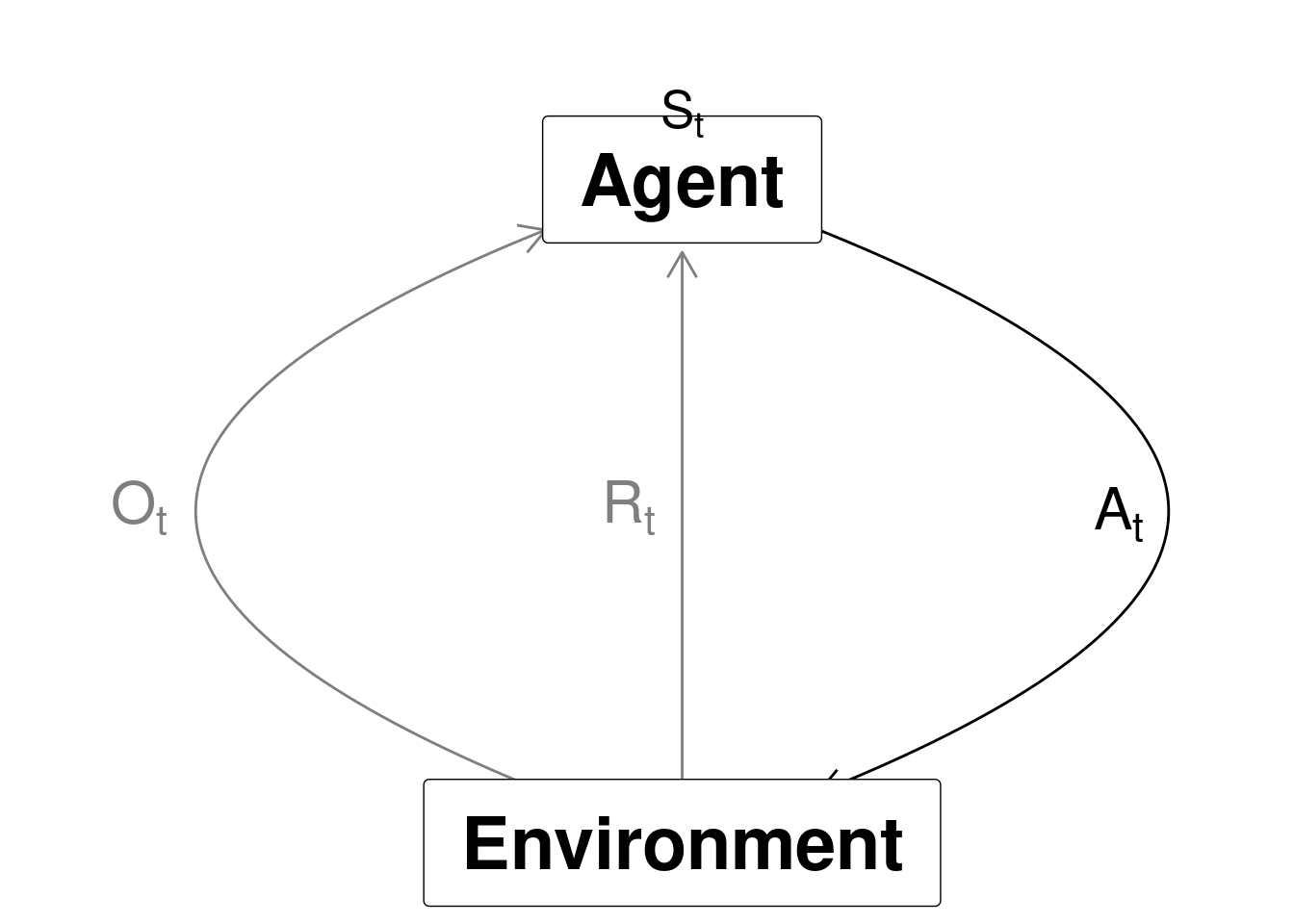
Figure 1.5: State and action.
A state depends on the history, i.e. a state is a function of the history \(S_t = f(H_t)\). Different strategies for defining a state may be considered. Choosing \(S_t = H_t\) is bad since the size of a state representation grows very fast. A better strategy is to just store the information needed for taking the next action. Moreover, it is good to have Markov states where given the present state the future is independent of the past. That is, the current state holds just as much information as the history, i.e. it holds all useful information of the history. Symbolically, we call a state \(S_t\) Markov iff
\[\Pr[S_{t+1} | S_t] = \Pr[S_{t+1} | S_1,...,S_t].\]
That is, the probability of seeing some next state \(S_{t+1}\) given the current state is exactly equal to the probability of that next state given the entire history of states. Note that we can always find some Markov state. Though the smaller the state, the more “valuable” it is. In the worst case, \(H_t\) is Markov, since it represents all known information about itself.
The reward \(R_t\) is a number representing the reward at time \(t\) (negative if a cost). Examples of rewards are
- Playing backgammon (0 (when play), 1 (when win), -1 (when loose)).
- How to invest/maintain a portfolio of stocks (the profit).
- Control an inventory (inventory cost, lost sales cost).
- Vehicle routing (transportation cost).
The goal is to find a policy that maximize the total future reward. A policy is the agent’s behaviour and is a map from state to action, i.e. a function \[a = \pi(s)\] saying that given the agent is in state \(s\) we choose action \(a\).
The total future reward is currently not defined clearly. Let the value function denote the future reward in state \(s\) and define it as the expected discounted future reward: \[V_\pi(s) = \mathbb{E}_\pi(R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} + \ldots | S = s).\] Note the value function is defined using a specific policy and the goal is to find a policy that maximize the total future reward in all possible states \[\pi^* = \arg\max_{\pi\in\Pi}(V_\pi(s)).\]
The value of the discount rate is important:
- Discount rate \(\gamma=0\): Only care about present reward.
- Discount rate \(\gamma=1\): Future reward is as beneficial as immediate reward. Can be used if the time-horizon is finite.
- Discount rate \(\gamma<1\): Rewards near to the present more beneficial. Note \(V(s)\) will converge to a number even if the time-horizon is infinite.
1.9 Exploitation vs Exploration
A key problem of reinforcement learning (in general) is the difference between exploration and exploitation. Should the agent sacrifice what is currently known as the best action to explore a (possibly) better opportunity, or should it just exploit its best possible policy? Exploitation takes the action assumed to be optimal with respect to the data observed so far. This, gives better predictions of the value function (given the current policy) but prevents the agent from discovering potential better decisions (a better policy). Exploration does not take the action that seems to be optimal. That is, the agent explore to find new states and update the value function for this state.
Examples in the exploration and exploitation dilemma are for instance movie recommendations: recommending the user’s best rated movie type (exploitation) or trying another movie type (exploration) or oil drilling: drilling at the best known location (exploitation) or trying a new location (exploration).
1.10 RL in action (Tic-Tac-Toe)
The current state of the board is represented by a row-wise concatenation of the players’ marks in a 3x3 grid. For example, the 9 character long string "......X.O" denotes a board state in which player X has placed a mark in the third row and first column whereas player O has placed a mark in the third row and the third column:
| . | . | . |
| . | . | . |
| X | . | O |
| 1 | 2 | 3 |
| 4 | 5 | 6 |
| 7 | 8 | 9 |
The game is continued until all fields are filled or the game is over (win or loose).
The player who succeeds in placing three of their marks in a horizontal, vertical, or diagonal row wins the game. Reward for a player is 1 for ‘win’, 0.5 for ‘draw’, and 0 for ‘loss’. These values can be seen as the probabilities of winning.
Examples of winning, loosing and a draw from player Xs point of view:
|
|
|
Note a state can also be represented using a state vector of length 9:
stateStr <- function(sV) {
str <- str_c(sV, collapse = "")
return(str)
}
stateVec <- function(s) {
sV <- str_split(s, "")[[1]]
return(sV)
}
sV <- stateVec("X.X.X.OOO")
sV
#> [1] "X" "." "X" "." "X" "." "O" "O" "O"Given a state vector, we can check if we win or loose:
#' Check board state
#'
#' @param pfx Player prefix (the char used on the board).
#' @param sV Board state vector.
#' @return A number 1 (win), 0 (loose) or 0.5 (draw/unknown)
win <- function(pfx, sV) {
idx <- which(sV == pfx)
mineV <- rep(0, 9)
mineV[idx] <- 1
mineM <- matrix(mineV, 3, 3, byrow = TRUE)
if (any(rowSums(mineM) == 3) || # win
any(colSums(mineM) == 3) ||
sum(diag(mineM)) == 3 ||
sum(mineM[1,3] + mineM[2,2] + mineM[3,1]) == 3) return(1)
idx <- which(sV == ".")
mineV[idx] <- 1
mineM <- matrix(mineV, 3, 3, byrow = TRUE)
if (any(rowSums(mineM) == 0) || # loose
any(colSums(mineM) == 0) ||
sum(diag(mineM)) == 0 ||
sum(mineM[1,3] + mineM[2,2] + mineM[3,1]) == 0) return(0)
return(0.5) # draw
}
win("O", sV)
#> [1] 1
win("X", sV)
#> [1] 0We start with an empty board and have at most 9 moves (a player may win before). If the opponent start and a state denote the board before the opponent makes a move, then a draw game may look as in Figure 1.6. We start with an empty board state \(S_0\), and the opponent makes a move, next we choose a move \(A_0\) (among the empty fields) and we end up in state \(S_1\). This continues until the game is over.
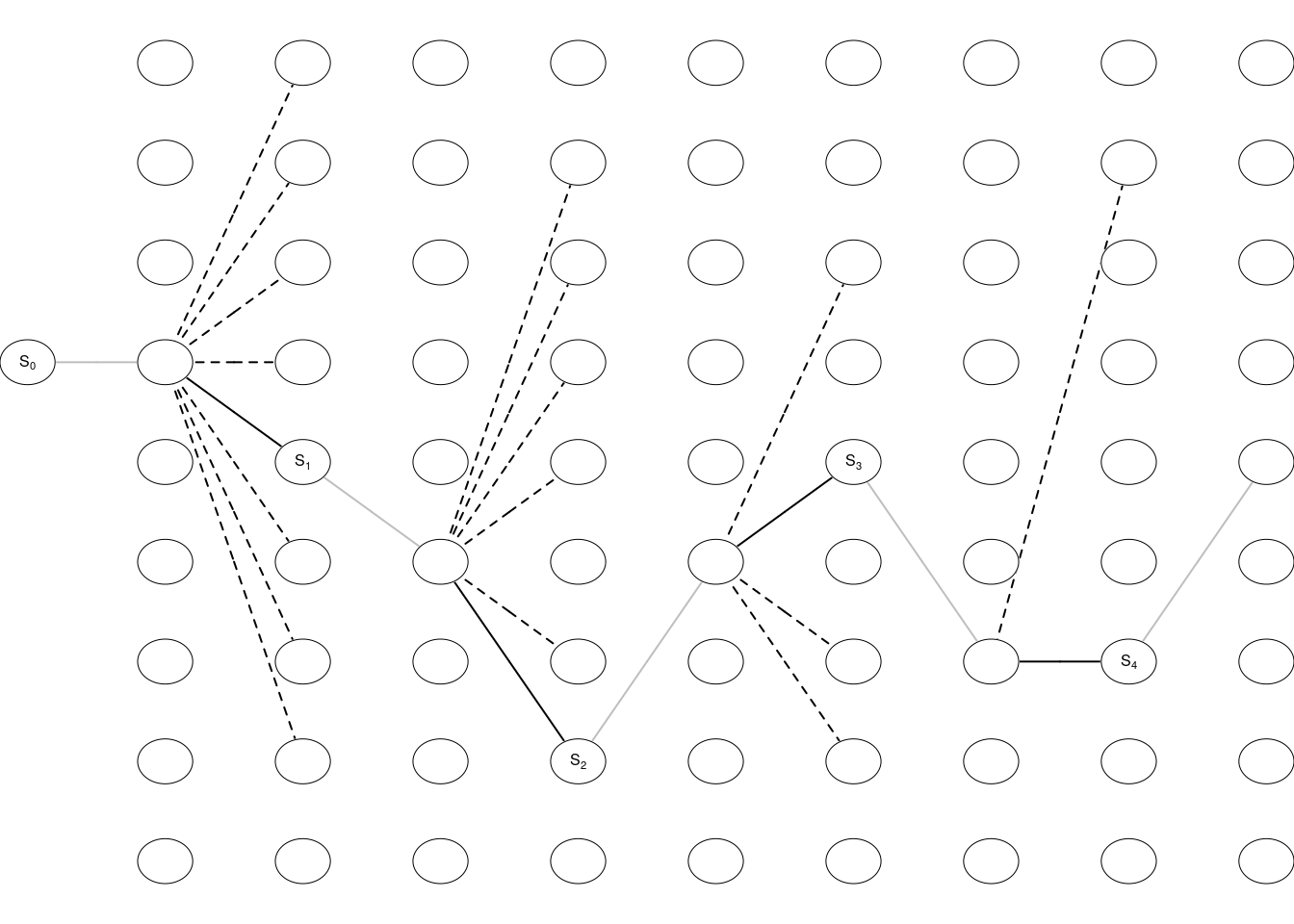
Figure 1.6: A draw.
1.10.1 Players and learning to play
Assume that we initially define a value \(V(S)\) of each state \(S\) to be 1 if we win, 0 if we loose and 0.5 otherwise. Most of the time we exploit our knowledge, i.e. choose the action which gives us the highest estimated reward (probability of winning). However, some times (with probability \(\epsilon\)) we explore and choose another action/move than what seems optimal. These moves make us experience states we may otherwise never see. If we exploit we update the value of a state using \[V(S_t) = V(S_t) + \alpha(V(S_{t+1})-V(S_t))\] where \(\alpha\) is the step-size parameter which influences the rate of learning.
Let us implement a RL player using a R6 class and store the values using a hash list. We keep the hash list minimal by dynamically adding only states which has been explored or needed for calculations. Note using R6 is an object oriented approach and objects are modified by reference. The internal method move takes the previous state (from our point of view) and the current state (before we make a move) and returns the next state (after our move) and update the value function (if exploit). The player explore with probability epsilon if there is not a next state that makes us win.
PlayerRL <- R6Class("PlayerRL",
public = list(
pfx = "", # player prefix
hV = NA, # empty hash list (states are stored using a string key)
control = list(epsilon = 0.2, alpha = 0.3),
clearLearning = function() clear(self$hV),
initialize = function(pfx = "", control = list(epsilon = 0.2, alpha = 0.3)) {
self$pfx <- pfx
self$control <- control
self$hV <- hash()
},
finalize = function() {
# cat("FIN\n")
clear(self$hV)
},
move = function(sP, sV) { # previous state (before opponent move) and current state (before we move)
idx <- which(sV == ".") # possible places to place our move
state <- stateStr(sP) # state as a string
if (!has.key(state, self$hV)) self$hV[[state]] <- 0.5 # if the state hasn't a value then set it to 0.5 (default)
# find possible moves and add missing states
keys <- c()
keysV <- NULL
for (i in idx) { # find possible moves
sV[i] <- self$pfx
str <- str_c(sV, collapse = "")
keys <- c(keys, str)
keysV <- rbind(keysV, sV)
sV[i] <- "." # set the value back to default
}
# add missing states of next sP
idx <- which(!has.key(keys, self$hV))
if (length(idx) > 0) {
for (i in 1:nrow(keysV)) {
self$hV[keys[i]] <- win(self$pfx, keysV[i,])
}
}
# cat("Player", pfx, "\n")
# print(self$hV)
# update and find next state
val <- values(self$hV[keys])
# cat("Moves:"); print(val)
m <- max(val)
if (rbinom(1,1, self$control$epsilon) > 0 & any(val < m) & m < 1) { # explore
idx <- which(val < m)
idx <- idx[sample(length(idx), 1)]
nextS <- names(val)[idx]
# cat("Explore - ")
} else { # exploit
idx <- which(val == m)
idx <- idx[sample(length(idx), 1)]
nextS <- names(val)[idx] # pick one
self$hV[[state]] <- self$hV[[state]] + self$control$alpha * (m - self$hV[[state]])
# cat("Exploit - ")
}
# cat("Next:", nextS, "\n")
return(str_split(nextS, "")[[1]])
}
)
)We then can define a player using:
Other players may be defined similarly, e.g. a player which moves randomly (if can not win in the next move):
PlayerRandom <- R6Class("PlayerRandom",
public = list(
pfx = NA,
initialize = function(pfx) {
self$pfx <- pfx
},
move = function(sP, sV) { # previous state (before opponent move) and current state (before we move)
idx <- which(sV == ".")
state <- stateStr(sV)
keys <- c()
keysV <- NULL
for (i in idx) { # find possible moves
sV[i] <- self$pfx
str <- str_c(sV, collapse = "")
keys <- c(keys, str)
keysV <- rbind(keysV, sV)
sV[i] <- "."
}
# check if can win in one move
for (i in 1:nrow(keysV)) {
if (win(self$pfx, keysV[i,]) == 1) {
return(keysV[i,]) # next state is the win state
}
}
# else pick one random
return(keysV[sample(nrow(keysV), 1),])
}
)
)A player which always place at the lowest field index:
1.10.2 Gameplay
We define a game which returns the prefix of the winner (NA if a draw):
#' @param player1 A player R6 object. This player starts the game
#' @param player2 A player R6 object.
#' @param verbose Print gameplay.
#' @return The winners prefix or NA if a tie.
playGame <- function(player1, player2, verbose = FALSE) {
sP2 <- rep(".", 9) # start state / game state
sP1 <- sP2 # state from player 1s viewpoint
for (i in 1:5) { # at most 4.5 rounds
## player 1
if (verbose) cat("Player ", player1$pfx, ":\n", sep="")
sP1 <- player1$move(sP1, sP2) # new state from player 1s viewpoint
# states <- c(states, stateChr(sV))
# cat(stateStr(sV), " | ", sep = "")
if (verbose) plot_board_state_cat(stateStr(sP1))
if (win(player1$pfx, sP1) == 1) {
return(player1$pfx)
break
}
if (i == 5) break # a draw
## player 2
if (verbose) cat("Player ", player2$pfx, ":\n", sep="")
sP2 <- player2$move(sP2, sP1)
# states <- c(states, stateChr(sV))
# cat(stateStr(sV), " | ", sep = "")
if (verbose) plot_board_state_cat(stateStr(sP2))
if (win(player2$pfx, sP2) == 1) {
return(player2$pfx)
break
}
}
return(NA)
}Let us play a game between playerA and playerR:
playerR <- PlayerRandom$new(pfx = "R")
playGame(playerA, playerR, verbose = T)
#> Player A:
#> |------------------|
#> | . | . | . |
#> |------------------|
#> | A | . | . |
#> |------------------|
#> | . | . | . |
#> |------------------|
#> Player R:
#> |------------------|
#> | R | . | . |
#> |------------------|
#> | A | . | . |
#> |------------------|
#> | . | . | . |
#> |------------------|
#> Player A:
#> |------------------|
#> | R | . | . |
#> |------------------|
#> | A | A | . |
#> |------------------|
#> | . | . | . |
#> |------------------|
#> Player R:
#> |------------------|
#> | R | . | . |
#> |------------------|
#> | A | A | . |
#> |------------------|
#> | . | R | . |
#> |------------------|
#> Player A:
#> |------------------|
#> | R | . | . |
#> |------------------|
#> | A | A | A |
#> |------------------|
#> | . | R | . |
#> |------------------|
#> [1] "A"Note playerA has been learning when playing the game. The current estimates that are stored in the hash list are:
playerA$hV
#> <hash> containing 22 key-value pair(s).
#> ......... : 0.5
#> ........A : 0.5
#> .......A. : 0.5
#> ......A.. : 0.5
#> .....A... : 0.5
#> ....A.... : 0.5
#> ...A..... : 0.5
#> ..A...... : 0.5
#> .A....... : 0.5
#> A........ : 0.5
#> R..A....A : 0.5
#> R..A...A. : 0.5
#> R..A..A.. : 0.5
#> R..A.A... : 0.5
#> R..AA.... : 0.55
#> R..AA..RA : 0.5
#> R..AA.AR. : 0.5
#> R..AAA.R. : 1
#> R.AA..... : 0.5
#> R.AAA..R. : 0.5
#> RA.A..... : 0.5
#> RA.AA..R. : 0.51.10.3 Learning by a sequence of games
With a single game only a few states are explored and estimates are not good. Let us instead play a sequence of games and learn along the way:
#' @param playerA Player A (R6 object).
#' @param playerB Player B (R6 object).
#' @param games Number of games
#' @param prA Probability of `playerA` starts.
#' @return A list with results (a data frame and a plot).
playGames <- function(playerA, playerB, games, prA = 0.5) {
winSeq <- rep(NA, games)
for (g in 1:games) {
# find start player
if (sample(0:1, 1, prob = c(prA, 1-prA)) == 0) {
player1 <- playerA
player2 <- playerB
} else {
player2 <- playerA
player1 <- playerB
}
winSeq[g] <- playGame(player1, player2)
}
# process the data
dat <- tibble(game = 1:length(winSeq), winner = winSeq) %>%
mutate(
players = str_c(playerA$pfx, playerB$pfx),
winA := case_when(
winner == playerA$pfx ~ 1,
winner == playerB$pfx ~ 0,
TRUE ~ 0.5
),
winsA_r = rollapply(winA, ceiling(games/10), mean, align = "right", fill = NA) #, fill = 0, partial = T
)
# make a plot
pt <- dat %>%
ggplot(aes(x = game, y = winA)) +
geom_line(aes(y = winsA_r), size = 0.2) +
geom_smooth(se = F) +
labs(y = str_c("Avg. wins player ", playerA$pfx),
title = str_c("Wins ", playerA$pfx, " = ", round(mean(dat$winA), 2), " ", playerB$pfx, " = ", round(1-mean(dat$winA), 2)))
return(list(dat = dat, plot = pt))
}Let us now play games against a player who moves randomly using \(\epsilon = 0.1\) (explore probability) and \(\alpha = 0.1\) (step size).
playerA <- PlayerRL$new(pfx = "A", control = list(epsilon = 0.1, alpha = 0.1))
playerR <- PlayerRandom$new(pfx = "R")
res <- playGames(playerA, playerR, games = 2000)
res$plot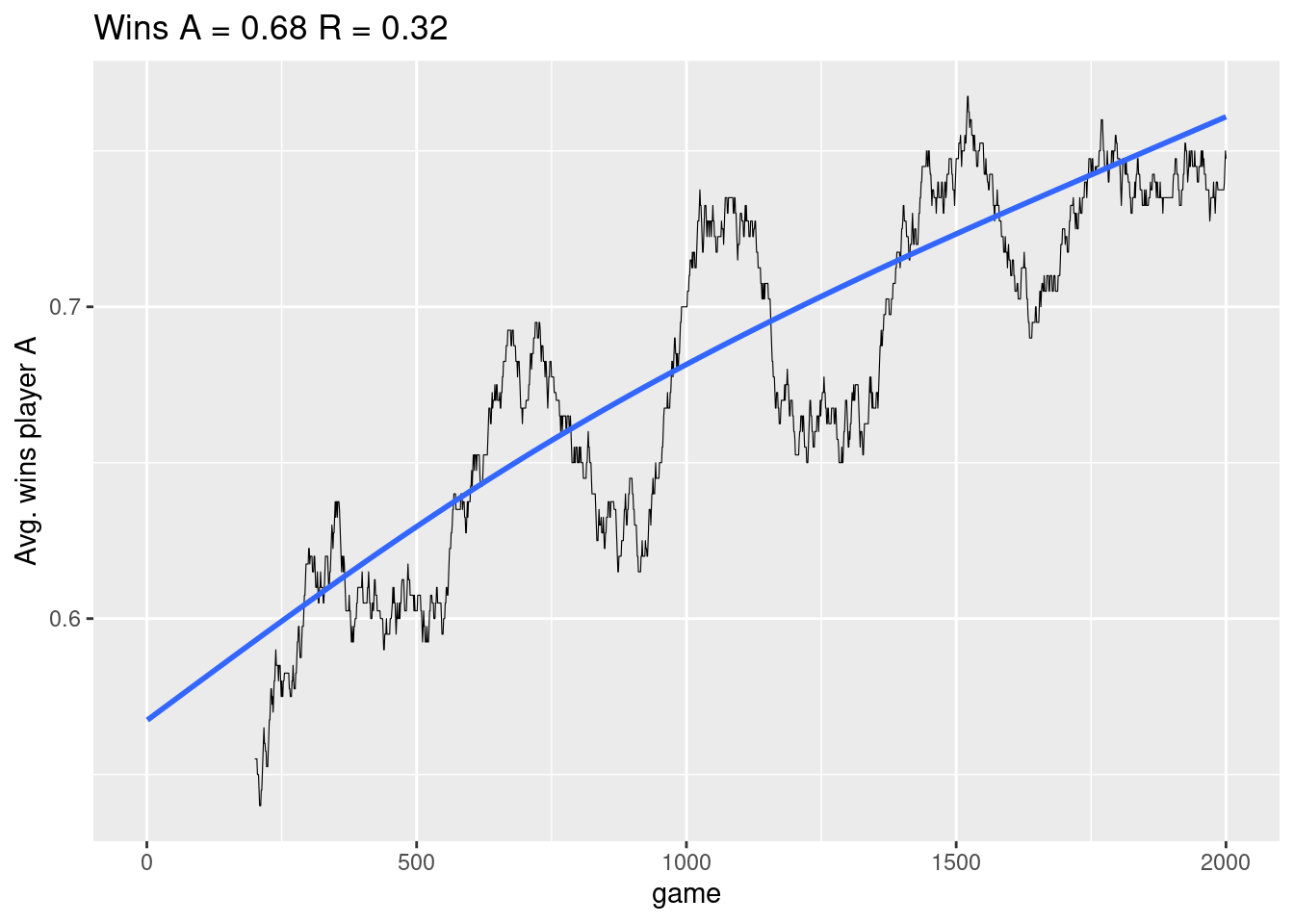
The black curve is the moving average of winning with a trend line. Note the values of the parameters have an effect on our learning:
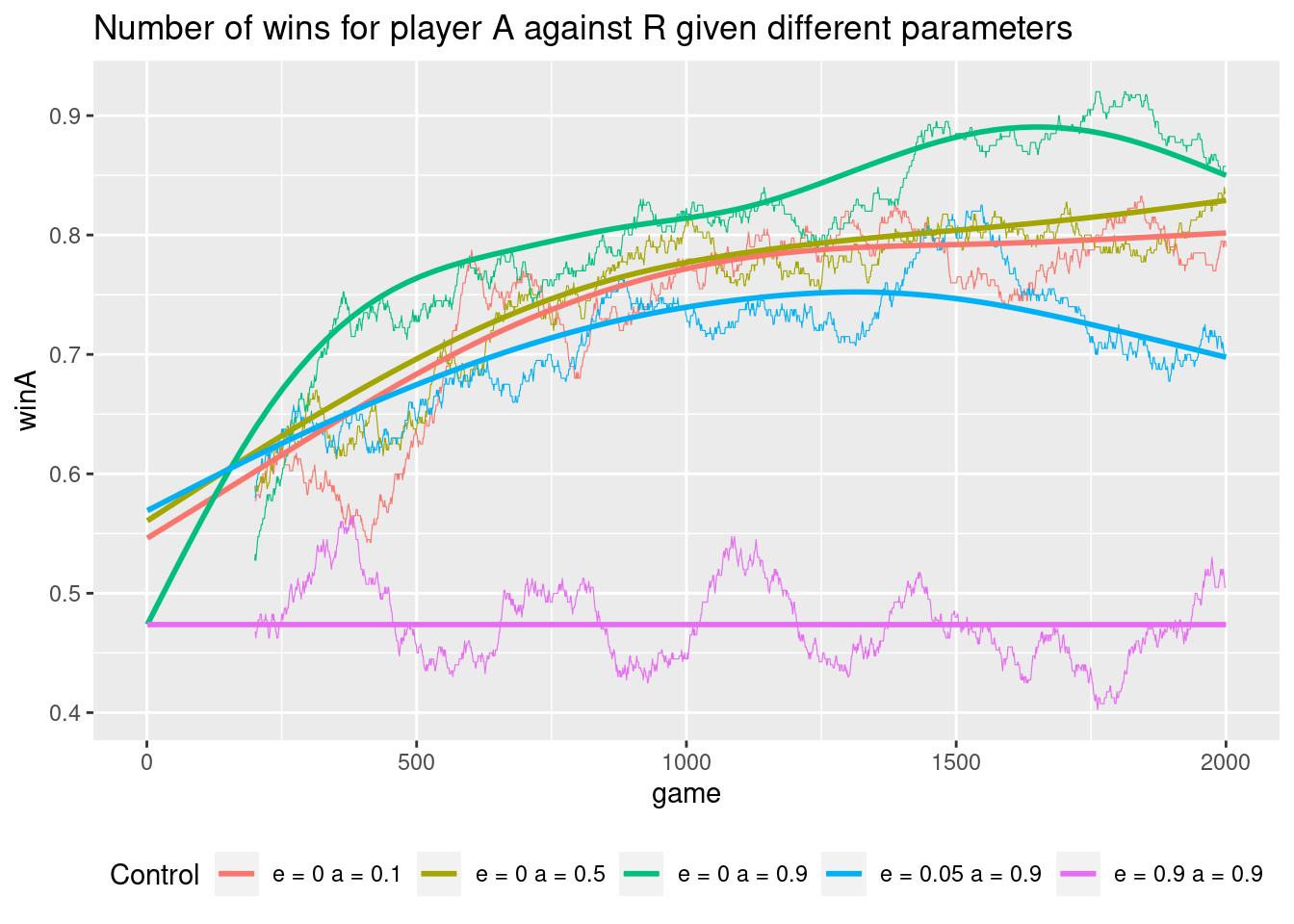
In general we do not need to explore (\(\epsilon = 0\)) (the other player explore enough for us) and a high explore probability (\(\epsilon = 0.9\)) make us loose. Moreover, using a high step size seems to work best.
Other players may give different results. If the RL player play against a player which always move to first free field index:
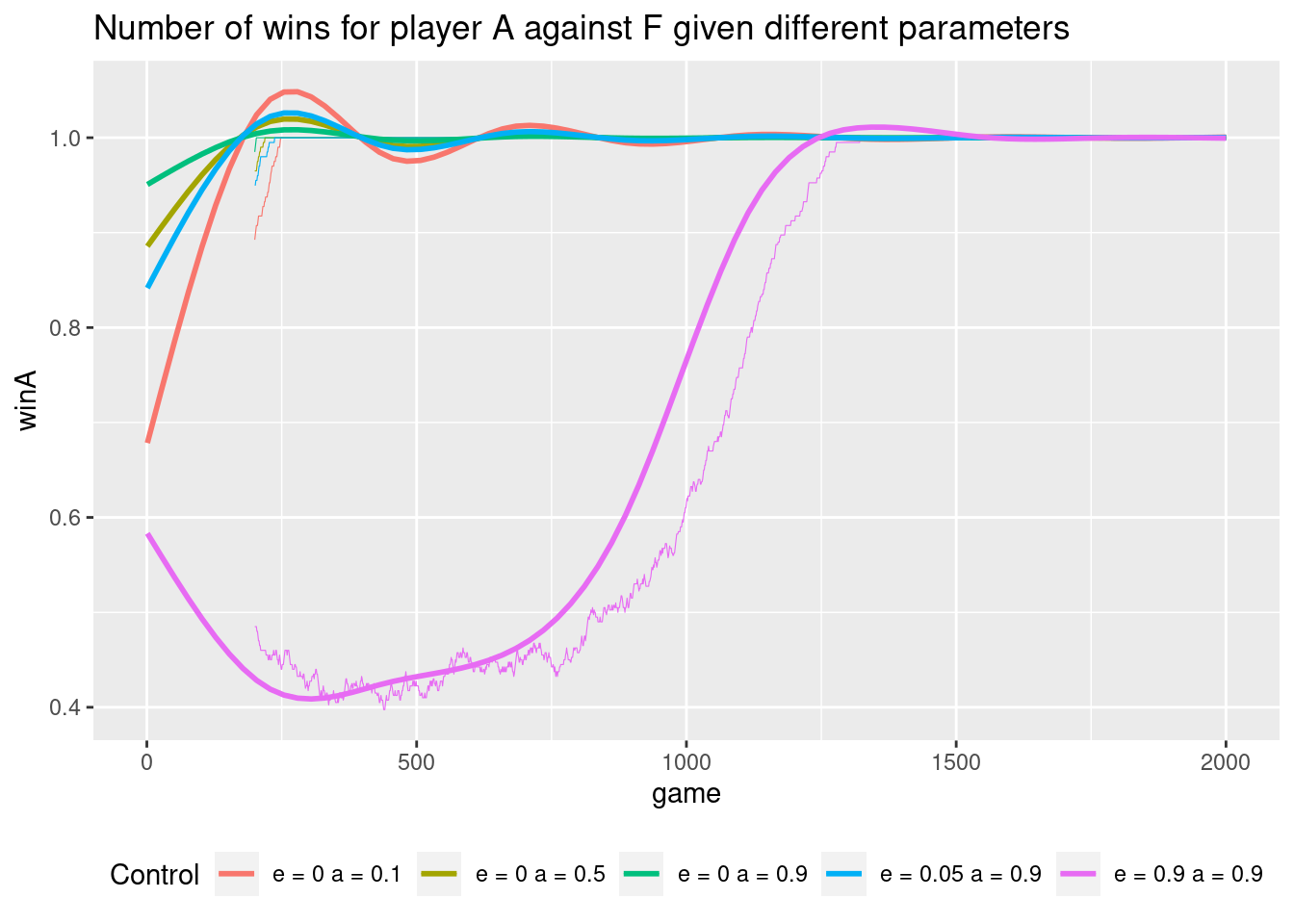
Here a high step size and a low exploration probability is good and the RL player will soon figure out how to win all the time.
This is different if the RL player A play against another clever (RL) player B.
playerA <- PlayerRL$new(pfx = "A", control = list(epsilon = 0, alpha = 0.1))
playerB <- PlayerRL$new(pfx = "B", control = list(epsilon = 0, alpha = 0.1))If both players play using the same control parameters, one would expect that they after learning should win/loose with probability 0.5. However if there is no exploration (\(\epsilon = 0\)) this is not always true:
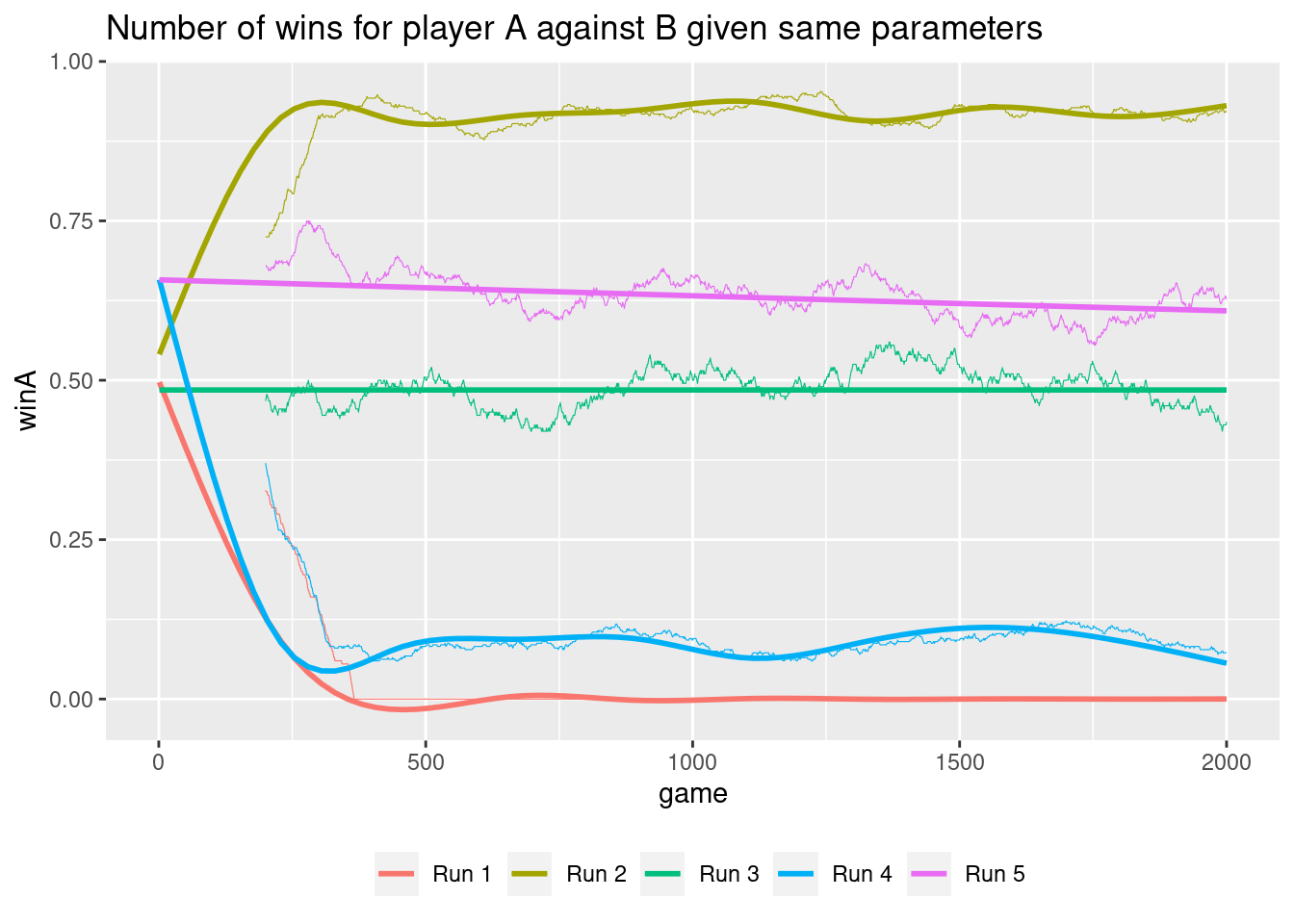
Depending on how the game starts a player may learn a better strategy and win/loose more. That is, exploration is important. Finally let us play against a player B with fixed control parameters.
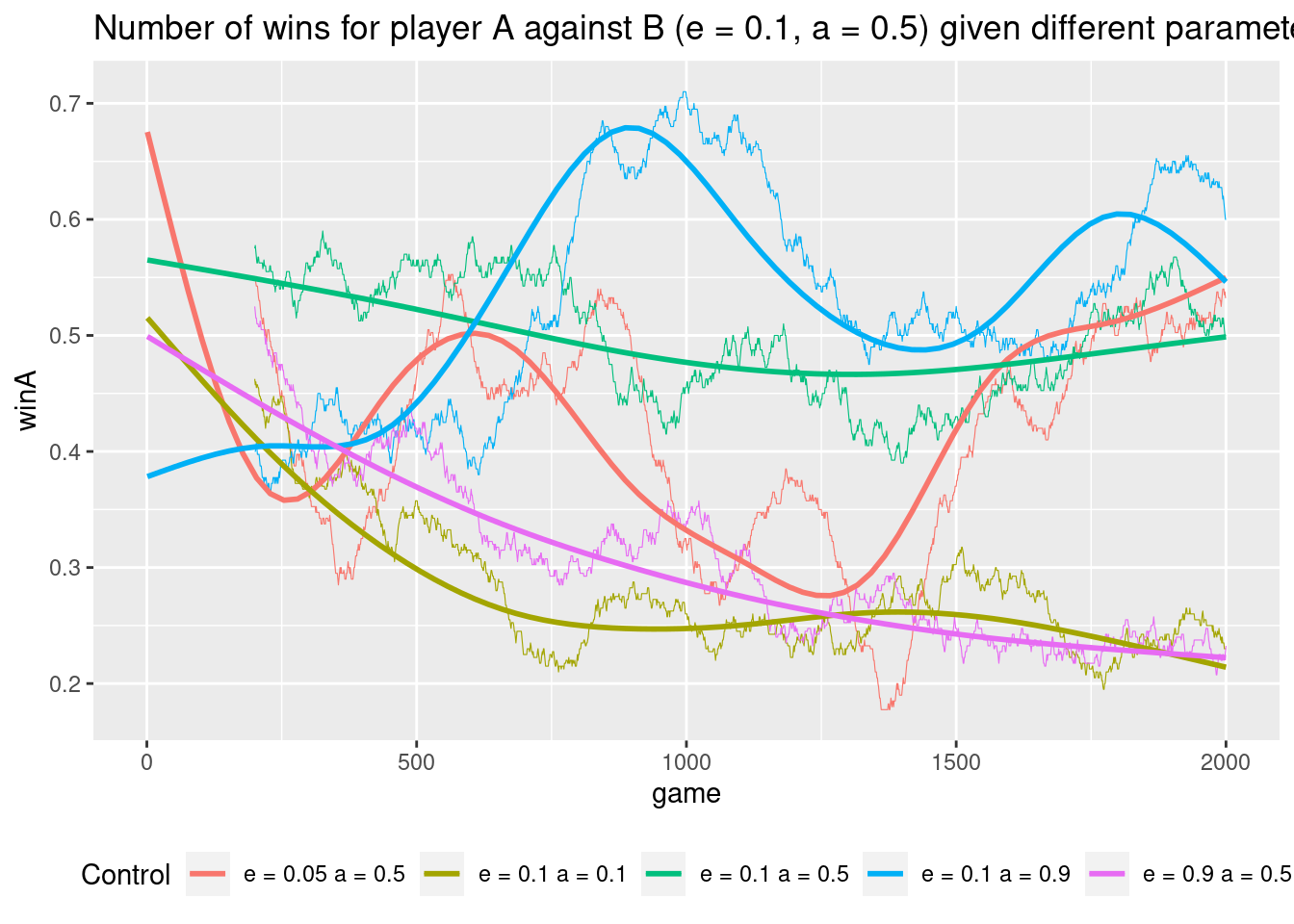
In general it is best to explore using the same probability otherwise you loose more and a higher step size than your opponent will make you win.
1.11 Summary
Read Chapter 1.6 in Sutton and Barto (2018).
1.12 Exercises
Below you will find a set of exercises. Always have a look at the exercises before you meet in your study group and try to solve them yourself. Are you stuck, see the help page. Sometimes solutions can be seen by pressing the button besides a question. Beware, you will not learn by giving up too early. Put some effort into finding a solution!
1.12.1 Exercise - Self-Play
Consider Tic-Tac-Toe and assume that instead of an RL player against a random opponent, the reinforcement learning algorithm described above played against itself. What do you think would happen in this case? Would it learn a different way of playing?
1.12.2 Exercise - Symmetries
Many tic-tac-toe positions appear different but are really the same because of symmetries.
- How might we amend the reinforcement learning algorithm described above to take advantage of this?
- In what ways would this improve the algorithm?
- Suppose the opponent did not take advantage of symmetries. In that case, should we? Is it true, then, that symmetrically equivalent positions should necessarily have the same value?
1.12.3 Exercise - Greedy Play
Consider Tic-Tac-Toe and suppose the RL player is only greedy (\(\epsilon = 0\)), that is, always playing the move that that gives the highest probability of winning. Would it learn to play better, or worse, than a non-greedy player? What problems might occur?
1.12.4 Exercise - Learning from Exploration
Consider Tic-Tac-Toe and suppose the RL player is playing against an opponent with a fixed strategy. Suppose learning updates occur after all moves, including exploratory moves. If the step-size parameter is appropriately reduced over time (but not the tendency to explore), then the state values would converge to a set of probabilities.
- What are the two sets of probabilities computed when we do, and when we do not, learn from exploratory moves?
- Assuming that we do continue to make exploratory moves, which set of probabilities might be better to learn? Which would result in more wins?