Module 2 Multi-armed bandits
This module consider the k-armed bandit problem which is a sequential decision problem with one state and \(k\) actions. The problem is used to illustrate different learning methods used in RL.
The module is also the first module in the Tabular methods part of the notes. This part describe almost all the core ideas of reinforcement learning algorithms in their simplest forms where the state and action spaces are small enough for the approximate value functions to be represented as arrays or tables.
2.1 Learning outcomes
By the end of this module, you are expected to:
- Define a k-armed bandit and understand the nature of the problem.
- Define the reward of a action (action-reward).
- Describe different methods for estimating the action-reward.
- Explain the differences between exploration and exploitation.
- Formulate an \(\epsilon\)-greedy algorithm for selecting the next action.
- Interpret the sample-average (variable step-size) versus exponential recency-weighted average (constant step-size) action-reward estimation.
- Argue why we might use a constant stepsize in the case of non-stationarity.
- Understand the effect of optimistic initial values.
- Formulate an upper confidence bound action selection algorithm.
The learning outcomes relate to the overall learning goals number 1, 3, 6, 9, 10 and 12 of the course.
2.2 Textbook readings
For this week, you will need to read Chapter 2 - 2.7 in Sutton and Barto (2018). Read it before continuing this module. A summary of the book notation can be seen here.
2.3 The k-armed bandit problem
Multi-armed bandits attempt to find the best option among a collection of alternatives by learning through trial and error. The name derives from “one-armed bandit,” a slang term for a slot machine — which is a perfect analogy for how these algorithms work.

Figure 2.1: A 4-armed bandit.
Imagine you are facing a wall with \(k\) slot machines (see Figure 2.1), and each one pays out at a different rate. A natural way to figure out how to make the most money (rewards) would be to try each at random for a while (exploration), and start playing the higher paying ones once you have gained some experience (exploitation). That is, from an agent/environment point of view the agent considers a single state \(s\) at time \(t\) and have to choose among \(k\) actions given the environment representing the \(k\) bandits. Only the rewards from the \(k\) bandits are unknown, but the agent observe samples of the reward of an action and can use this to estimate the expected reward of that action. The objective is to find an optimal policy that maximize the total expected reward. Note since the process only have a single state, this is the same as finding an optimal policy \(\pi^*(s) = \pi^* = a^*\) that chooses the action with the highest expected reward. Due to uncertainty, there is an exploration vs exploitation dilemma. The agent have one action that seems to be most valuable at a time point, but it is highly likely, at least initially, that there are actions yet to explore that are more valuable.
Multi-armed bandits can be used in e.g. digital advertising. Suppose you are an advertiser seeking to optimize which ads (\(k\) to choose among) to show visitors on a particular website. For each visitor, you can choose one out of a collection of ads, and your goal is to maximize the number of clicks over time.

Figure 2.2: Which ad to choose?
It is reasonable to assume that each of these ads will have different effects, and some will be more engaging than others. That is, each ad has some theoretical — but unknown — click-through-rate (CTR) that is assumed to not change over time. How do we go about solving which ad we should choose (see Figure 2.2)?
2.4 Estimating the value of an action
How can the value of an action be estimated, i.e. the expected reward of an action \(q_*(a) = \mathbb{E}[R_t | A_t = a]\). Assume that at time \(t\) action \(a\) has been chosen \(N_t(a)\) times. Then the estimated action value is \[\begin{equation} Q_t(a) = \frac{R_1+R_2+\cdots+R_{N_t(a)}}{N_t(a)}, \end{equation}\] Storing \(Q_t(a)\) this way is cumbersome since memory and computation requirements grow over time. Instead an incremental approach is better. If we assume that \(N_t(a) = n-1\) and set \(Q_t(a) = Q_n\) then \(Q_{n+1}\) becomes: \[\begin{align} Q_{n+1} &= \frac{1}{n}\sum_{i=1}^{n}R_i \nonumber \\ &= \frac{1}{n}\left( R_{n} + \sum_{i=1}^{n-1} R_i \right) \nonumber \\ &= \frac{1}{n}\left( R_{n} + (n-1)\frac{1}{n-1}\sum_{i=1}^{n-1} R_i \right) \nonumber \\ &= \frac{1}{n}\left( R_{n} + (n-1)Q_n \right) \nonumber \\ &= Q_n + \frac{1}{n} \left[R_n - Q_n\right]. \tag{2.1} \end{align}\] That is, we can update the estimate of the value of \(a\) using the previous estimate, the observed reward and how many times the action has occurred (\(n\)).
A greedy approach for selecting the next action is \[\begin{equation} A_t =\arg \max_a Q_t(a). \end{equation}\] Here \(\arg\max_a\) means the value of \(a\) for which \(Q_t(a)\) is maximised. A pure greedy approach do not explore other actions. Instead an \(\varepsilon\)-greedy approach is used in which with probability \(\varepsilon\) we take a random draw from all of the actions (choosing each action with equal probability) and hereby providing some exploration.
Let us try to implement the algorithm using an agent and environment class. First we define the agent that do actions based on an \(\epsilon\)-greedy strategy, stores the estimated \(Q\) values and the number of times an action has been chosen:
#' R6 Class representing the RL agent
RLAgent <- R6Class("RLAgent",
public = list(
#' @field qV Q estimates.
qV = NULL,
#' @field nV Action counter.
nV = NULL,
#' @field k Number of bandits.
k = NULL,
#' @field epsilon Epsilon used in epsilon greed action selection.
epsilon = NULL,
#' @description Create an object (when call new).
#' @param k Number of bandits.
#' @param epsilon Epsilon used in epsilon greed action selection.
#' @param ini Initial qV values.
#' @return The new object.
initialize = function(k = 10, epsilon = 0.01, ini = 0) {
self$epsilon <- epsilon
self$qV <- rep(ini, k) # k-length vector
self$nV <- rep(0, k) # k-length vector
self$k <- k
},
#' @description Clear learning.
clearLearning = function() {
self$qV <- 0
self$nV <- 0
},
#' @description Select next action using an epsilon greedy strategy.
#' @return Action (index).
selectActionEG = function() {
if (runif(1) <= self$epsilon) { # explore
a <- sample(1:self$k, 1)
} else { # exploit
a <- which(self$qV == max(self$qV))
a <- a[sample(length(a), 1)] # choose a action random if more than one
}
return(a)
},
#' @description Update learning values (including action counter).
#' @param a Action.
#' @param r Reward.
#' @return NULL (invisible)
updateQ = function(a, r) {
self$nV[a] <- self$nV[a] + 1
self$qV[a] <- self$qV[a] + 1/self$nV[a] * (r - self$qV[a])
return(invisible(NULL))
}
)
)Next, the environment generating rewards. The true mean reward \(q_*(a)\) of an action is selected according to a normal (Gaussian) distribution with mean 0 and variance 1. The observed reward is then generated using a normal distribution with mean \(q_*(a)\) and variance 1:
#' R6 Class representing the RL environment
#'
#' Assume that bandits are normal distributed with a mean and std.dev of one.
RLEnvironment <- R6Class("RLEnvironment",
public = list(
#' @field mV Mean values
mV = NULL,
#' @field k Number of bandits.
k = NULL,
#' @description Create an object (when call new).
#' @param k Number of bandits.
#' @return The new object.
initialize = function(k = 10) {
self$mV <- rnorm(k) # means are from a N(0,1)
},
#' @description Sample reward of a bandit.
#' @param a Bandit (index).
#' @return The reward.
reward = function(a) {
return(rnorm(1, self$mV[a])) # pick a random value from N(self$mV[a],1)
},
#' @description Returns action with best mean.
optimalAction = function() return(which.max(self$mV))
)
)To test the RL algorithm we use a function returning two plots that compare the performance:
#' Performance of the bandit algorithm using different epsilons.
#'
#' @param k Bandits.
#' @param steps Time steps.
#' @param runs Number of runs with a new environment generated.
#' @param epsilons Epsilons to be tested.
#' @param ini Initial value estimates.
#' @return Two plots in a list.
performance <- function(k = 10, steps = 1000, runs = 500,
epsilons = c(0, 0.01, 0.1), ini = 0) {
rew <- matrix(0, nrow = steps, ncol = length(epsilons)) # rewards (one col for each eps)
best <- matrix(0, nrow = steps, ncol = length(epsilons)) # add 1 if find the best action
for (run in 1:runs) {
env <- RLEnvironment$new(k)
oA <- env$optimalAction()
# print(oA); print(env$mV)
for (i in 1:length(epsilons)) {
agent <- RLAgent$new(k, epsilons[i], ini)
for (t in 1:steps) {
a <- agent$selectActionEG()
r <- env$reward(a)
agent$updateQ(a, r)
rew[t, i] <- rew[t, i] + r # sum of rewards generated at t
best[t, i] <- best[t, i] + (a == oA) # times find best actions
}
}
}
colnames(rew) <- epsilons
colnames(best) <- epsilons
dat1 <- tibble(t = 1:steps) %>%
bind_cols(rew) %>% # bind data together
pivot_longer(!t, values_to = "reward", names_to = "epsilon") %>% # move rewards to a single column
group_by(epsilon) %>%
mutate(All = cumsum(reward/runs)/t, `Moving avg (50)` = rollapply(reward/runs, 50, mean, align = "right", fill = NA)) %>%
select(-reward) %>%
pivot_longer(!c(t, epsilon))
dat2 <- tibble(t = 1:steps) %>%
bind_cols(best) %>% # bind data together
pivot_longer(!t, values_to = "optimal", names_to = "epsilon") %>%
group_by(epsilon) %>%
mutate(All = cumsum(optimal/runs)/t, `Moving avg (50)` = rollapply(optimal/runs, 50, mean, align = "right", fill = NA)) %>%
select(-optimal) %>%
pivot_longer(!c(t, epsilon))
# calc average
pt1 <- dat1 %>%
ggplot(aes(x = t, y = value, col = epsilon, linetype = name)) +
geom_line() +
labs(y = "Average reward per time unit", x = "Time", title = str_c("Average over ", runs, " runs "), col = "Epsilon", linetype = "") +
theme(legend.position = "bottom")
pt2 <- dat2 %>%
ggplot(aes(x = t, y = value, col = epsilon, linetype = name)) +
geom_line() +
labs(y = "Average number of times optimal action chosen", x = "Time", title = str_c("Average over ", runs, " runs"), col = "Epsilon", linetype = "") +
theme(legend.position = "bottom")
return(list(ptR = pt1, ptO = pt2))
}We test the performance using 2000 runs over 1000 time steps.
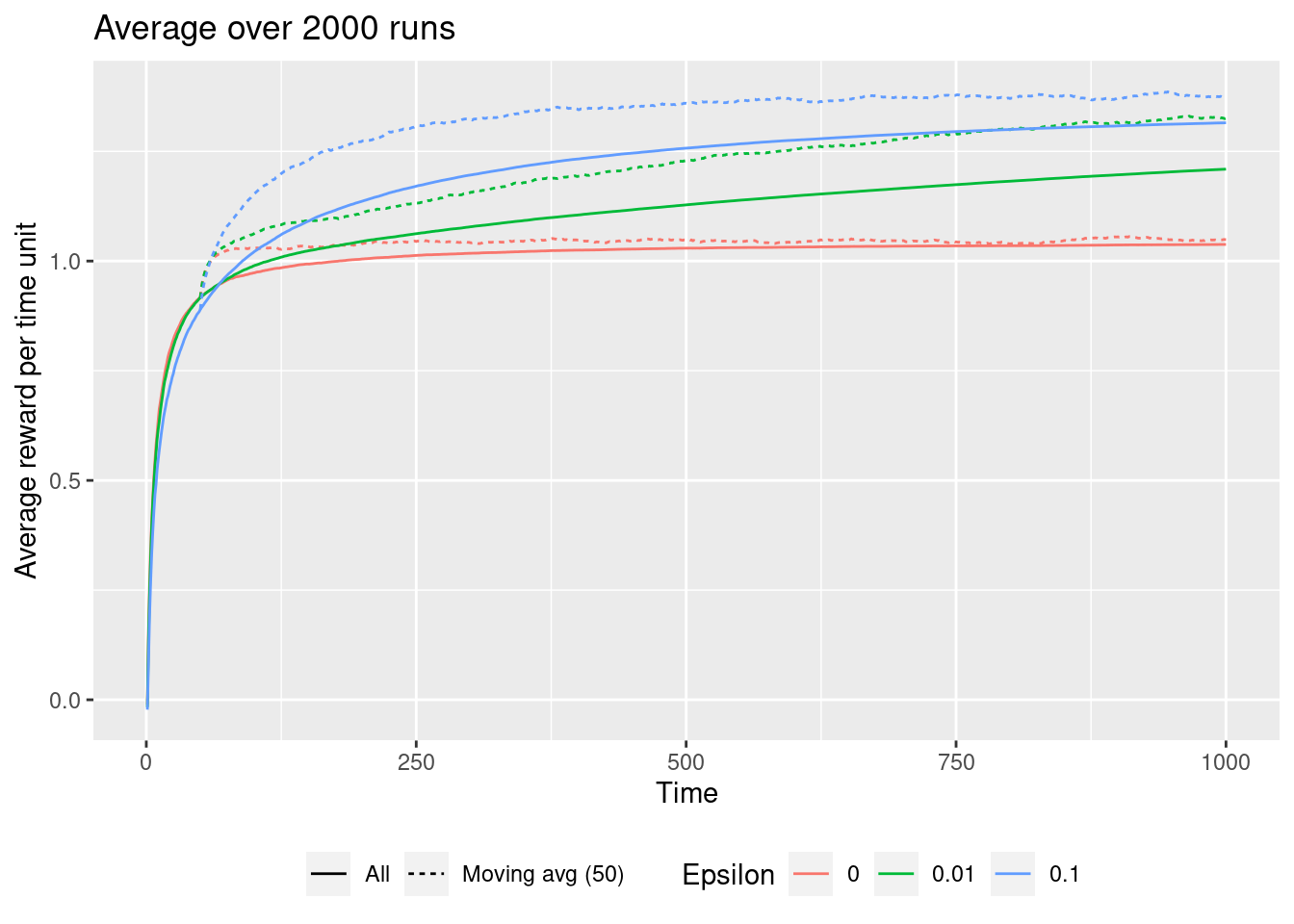
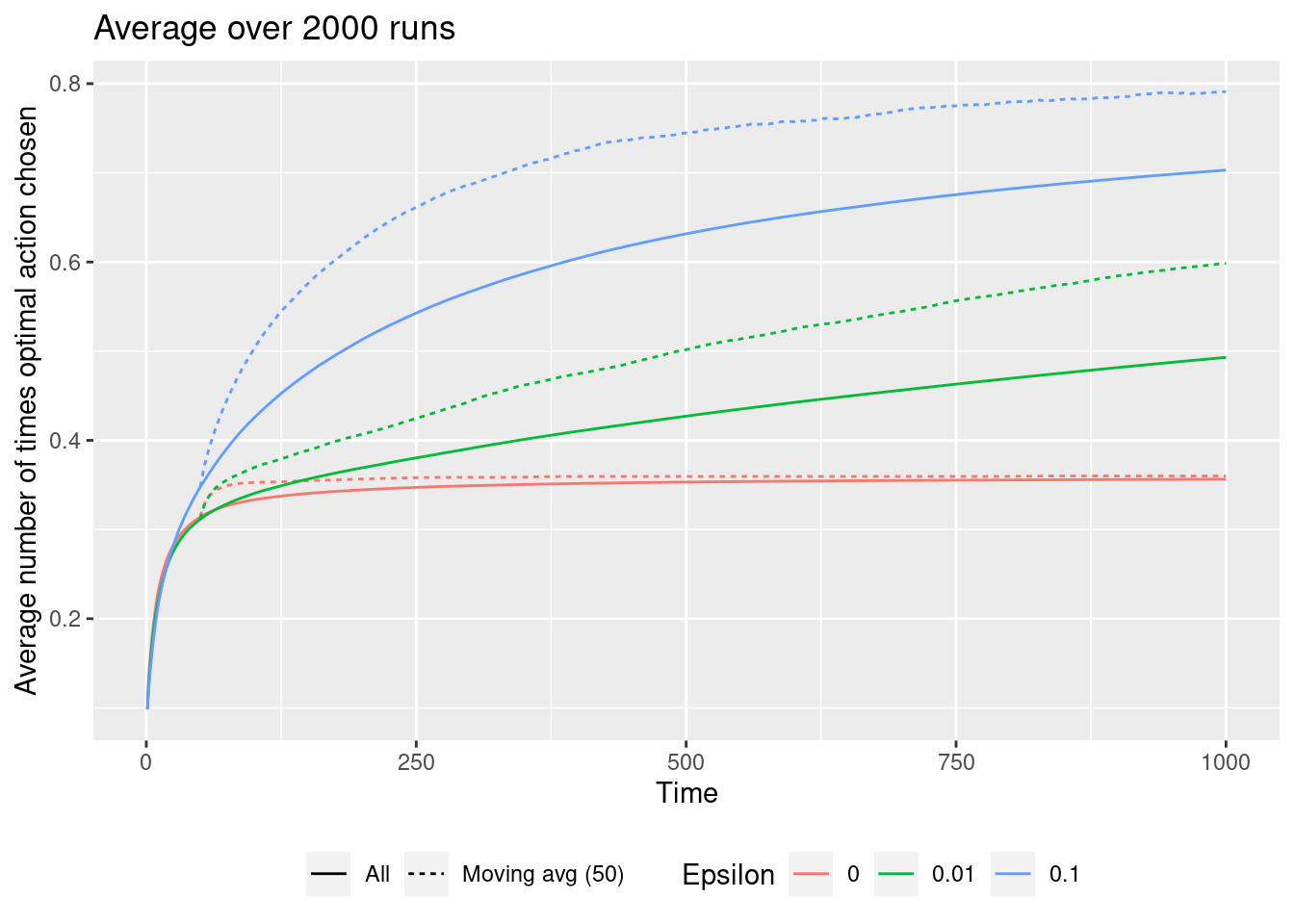
The solid line shows averages over all the runs from \(t=1\) to the considered time-step while the dotted line is a moving average over the last 50 time-steps. Since we are expected to learn over the time-steps the moving averages will in general be higher than the overall averages. Note that if we have 1000 time-steps a greedy approach in general is bad and an \(\epsilon\)-greedy approach is better (\(\epsilon = 0.1\) is best). That is, exploration is beneficial.
2.5 The role of the step-size
In general we update the reward estimate of an action using
\[\begin{equation} Q_{n+1} = Q_n +\alpha_n(a) \left[R_n - Q_n\right] \end{equation}\]
Until now we have used the sample average \(\alpha_n(a)= 1/n\); however, other choices of \(\alpha_n(a)\) is possible. In general we will converge to the true reward if
\[\begin{equation} \sum_n \alpha_n(a) = \infty \quad\quad \mathsf{and} \quad\quad \sum_n \alpha_n(a)^2 < \infty. \end{equation}\]
Meaning that the coefficients must be large enough to recover from initial fluctuations, but not so large that they do not converge in the long run. However, if the process is non-stationary, i.e. the expected reward of an action change over time, then convergence is undesirable and we may want to use a constant \(\alpha_n(a)= \alpha \in (0, 1]\) instead. This results in \(Q_{n+1}\) being a weighted average of the past rewards and the initial estimate \(Q_1\):
\[\begin{align} Q_{n+1} &= Q_n +\alpha \left[R_n - Q_n\right] \nonumber \\ &= \alpha R_n + (1 - \alpha)Q_n \nonumber \\ &= \alpha R_n + (1 - \alpha)[\alpha R_{n-1} + (1 - \alpha)Q_{n-1}] \nonumber \\ &= \alpha R_n + (1 - \alpha)\alpha R_{n-1} + (1 - \alpha)^2 Q_{n-1} \nonumber \\ &= \vdots \nonumber \\ &= (1-\alpha)^n Q_1 + \sum_{i=1}^{n} \alpha (1 - \alpha)^{n-i} R_i \\ \end{align}\]
Because the weight given to each reward depends on how long ago it was observed, we can see that more recent rewards are given more weight. Note the weights \(\alpha\) sum to 1 here, ensuring it is indeed a weighted average where more weight is allocated to recent rewards. Since the weight given to each reward decays exponentially into the past. This sometimes called an exponential recency-weighted average.
2.6 Optimistic initial values
The methods discussed so far are dependent to some extent on the initial action-value estimate i.e. they are biased by their initial estimates. For methods with constant \(\alpha\) this bias is permanent. We may set initial value estimates artificially high to encourage exploration in the short run. For instance, by setting initial values of \(Q\) to 5 rather than 0 we encourage exploration, even in the greedy case. Here the agent will almost always be disappointed with it’s samples because they are less than the initial estimate and so will explore elsewhere until the values converge.
2.7 Upper-Confidence Bound Action Selection
An \(\epsilon\)-greed algorithm choose the action to explore with equal probability in an exploration step. It would be better to select among non-greedy actions according to their potential for actually being optimal, taking into account both how close their estimates are to being maximal and the uncertainty in those estimates. One way to do this is to select actions using the upper-confidence bound: \[\begin{equation} A_t = \arg\max_a \left(Q_t(a) + c\sqrt{\frac{\ln t}{N_t(a)}}\right), \end{equation}\]
Note the square root term is a measure of the uncertainty in our estimate (see Figure 2.3).
- It is proportional to \(t\) i.e. how many time-steps have passed and inversely proportional to \(N_t(a)\) i.e. how many times that action has been visited.
- The more time has passed, and the less we have sampled an action, the higher our upper-confidence-bound.
- As the timesteps increases, the denominator dominates the numerator as the ln term flattens.
- Each time we select an action our uncertainty decreases because \(N\) is the denominator of this equation.
- If \(N_t(a) = 0\) then we consider \(a\) as a maximal action, i.e. we select first among actions with \(N_t(a) = 0\).
- The parameter \(c>0\) controls the degree of exploration. Higher \(c\) results in more weight on the uncertainty.
Since upper-confidence bound action selection select actions according to their potential, it is expected to perform better than \(\epsilon\)-greedy methods.
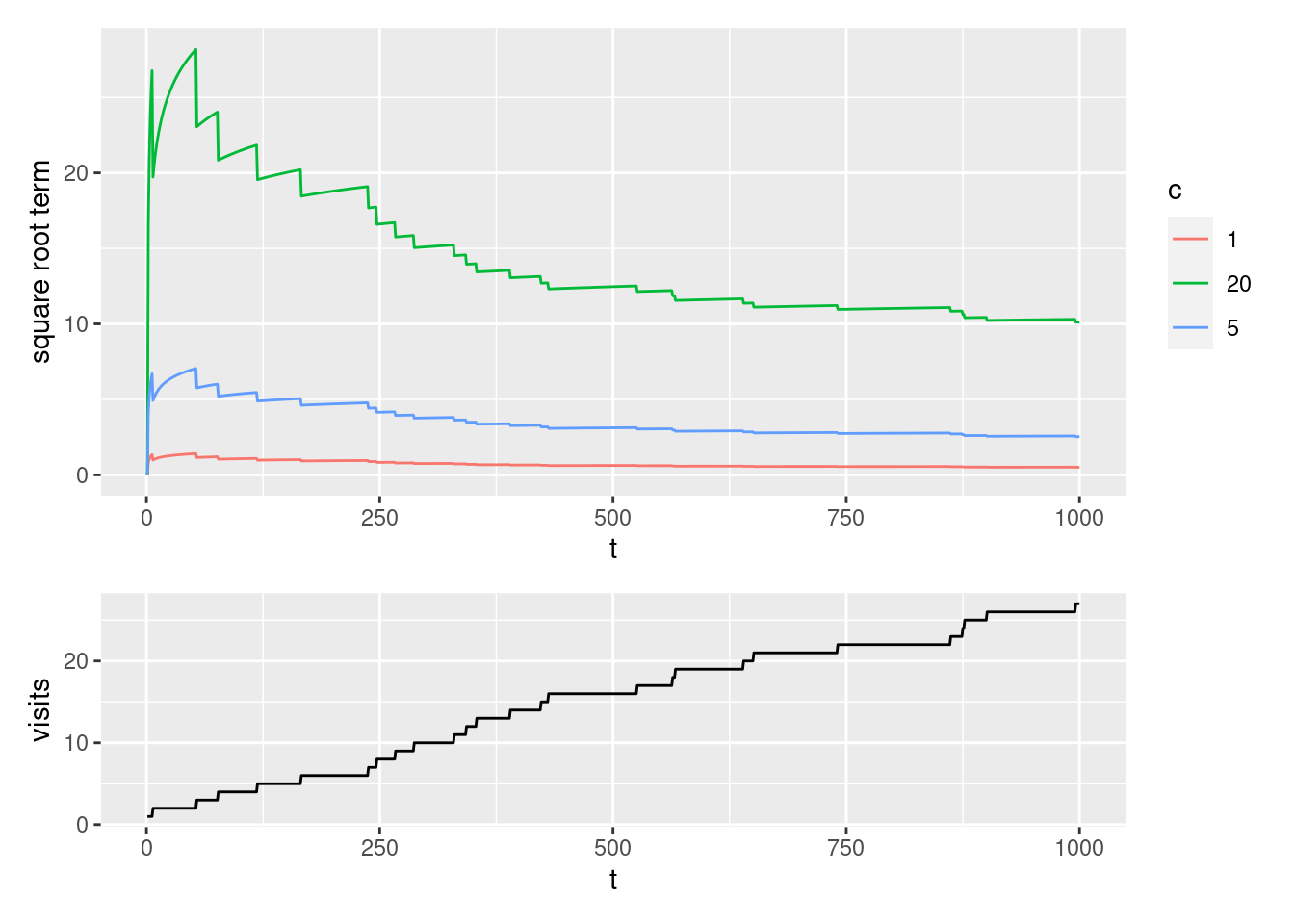
Figure 2.3: Square root term for an action using different \(c\)-values.
2.8 Summary
Read Chapter 2.10 in Sutton and Barto (2018).
2.9 Exercises
Below you will find a set of exercises. Always have a look at the exercises before you meet in your study group and try to solve them yourself. Are you stuck, see the help page. Sometimes solutions can be seen by pressing the button besides a question. Beware, you will not learn by giving up too early. Put some effort into finding a solution!
2.9.1 Exercise - Advertising
Suppose you are an advertiser seeking to optimize which ads to show visitors on a particular website. For each visitor, you can choose one out of a collection of ads, and your goal is to maximize the number of clicks over time. Assume that:
- You have \(k=5\) adds to choose among.
- If add \(A\) is chosen then the user clicks the add with probability \(p_A\) which can be seen as the unknown click trough rate CTR (or an average reward).
- The CTRs are unknown and samples can be picked using the
RLAdEnvclass and the reward function which returns 1 if click on ad and 0 otherwise.
#' R6 Class representing the RL advertising environment
RLAdEnv <- R6Class("RLAdEnv",
public = list(
#' @field mV Click trough rates (unknown to you)
mV = c(0.1, 0.83, 0.85, 0.5, 0.7),
#' @field k Number of ads.
k = 5,
#' @description Sample reward of a bandit.
#' @param a Bandit/ad (index).
#' @return One if click on ad and zero otherwise.
reward = function(a) {
return(rbinom(1, 1, self$mV[a]))
},
#' @description Returns action with best mean.
optimalAction = function() return(which.max(self$mV))
)
)
env <- RLAdEnv$new()
env$reward(2) # click on ad number two (return 0 or 1)?
#> [1] 1
env$optimalAction() # the best ad
#> [1] 3
env$mV # true CTRs
#> [1] 0.10 0.83 0.85 0.50 0.70In the class the true CTRs can be observed but in practice this is hidden from the agent (you).
Consider an \(\epsilon\)-greedy algorithm to find the best ad. Assume the webpage is visited by 10000 users per day.
- Run the \(\epsilon\)-greedy algorithm with \(\epsilon = 0.01, 0.1, 0.5\) over the 10000 steps. What are the estimated CTRs for each action (\(Q_t(a)\))? What is the average number of clicks per user?
Solution
## Test function modified with plot feature
testEG <- function(epsilon, steps = 10000) {
agent <- RLAgent$new(k = 5, epsilon = epsilon)
rew <- 0
qVal <- matrix(0, nrow = steps, ncol = 5) # store qV in a row for each t
colnames(qVal) = str_c("A", 1:5)
for (t in 1:steps) {
a <- agent$selectActionEG()
r <- env$reward(a)
rew <- rew + r
agent$updateQ(a, r)
qVal[t,] <- agent$qV
}
# make plot
dat <- tibble(t = 1:steps) %>%
bind_cols(qVal) %>% # bind data together
pivot_longer(!t, values_to = "ctr", names_to = "action")
pt <- dat %>%
ggplot(aes(x = t, y = ctr, col = action)) +
geom_line() +
labs(y = "Empirical CTRs", x = "Time", title = str_c("CTRs eps = ", epsilon), col = "Action") +
theme(legend.position = "bottom")
return(list(qV = agent$qV, avgReward = rew/steps, plt = pt))
}
testEG(0.01)$plt
testEG(0.5)$plt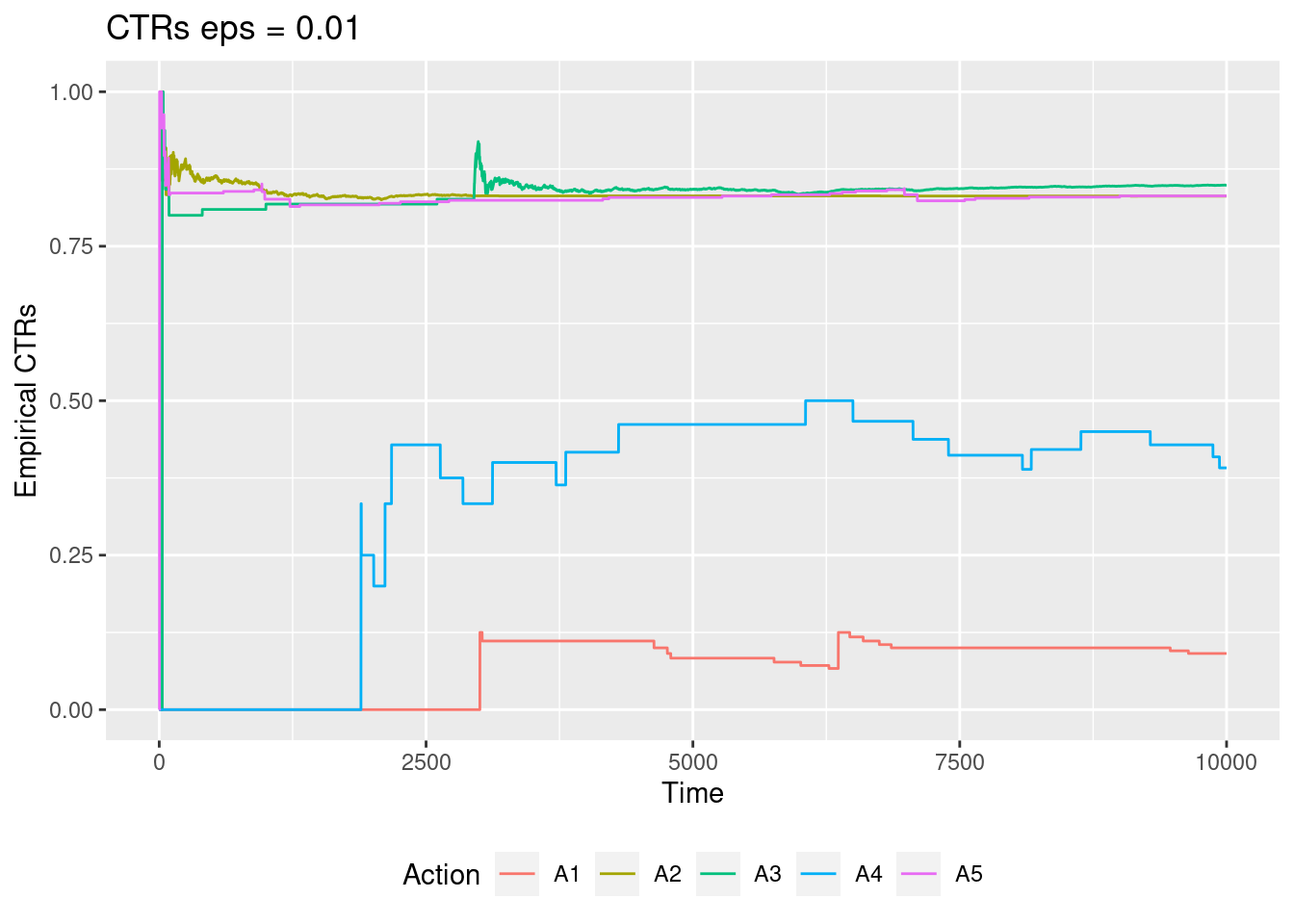
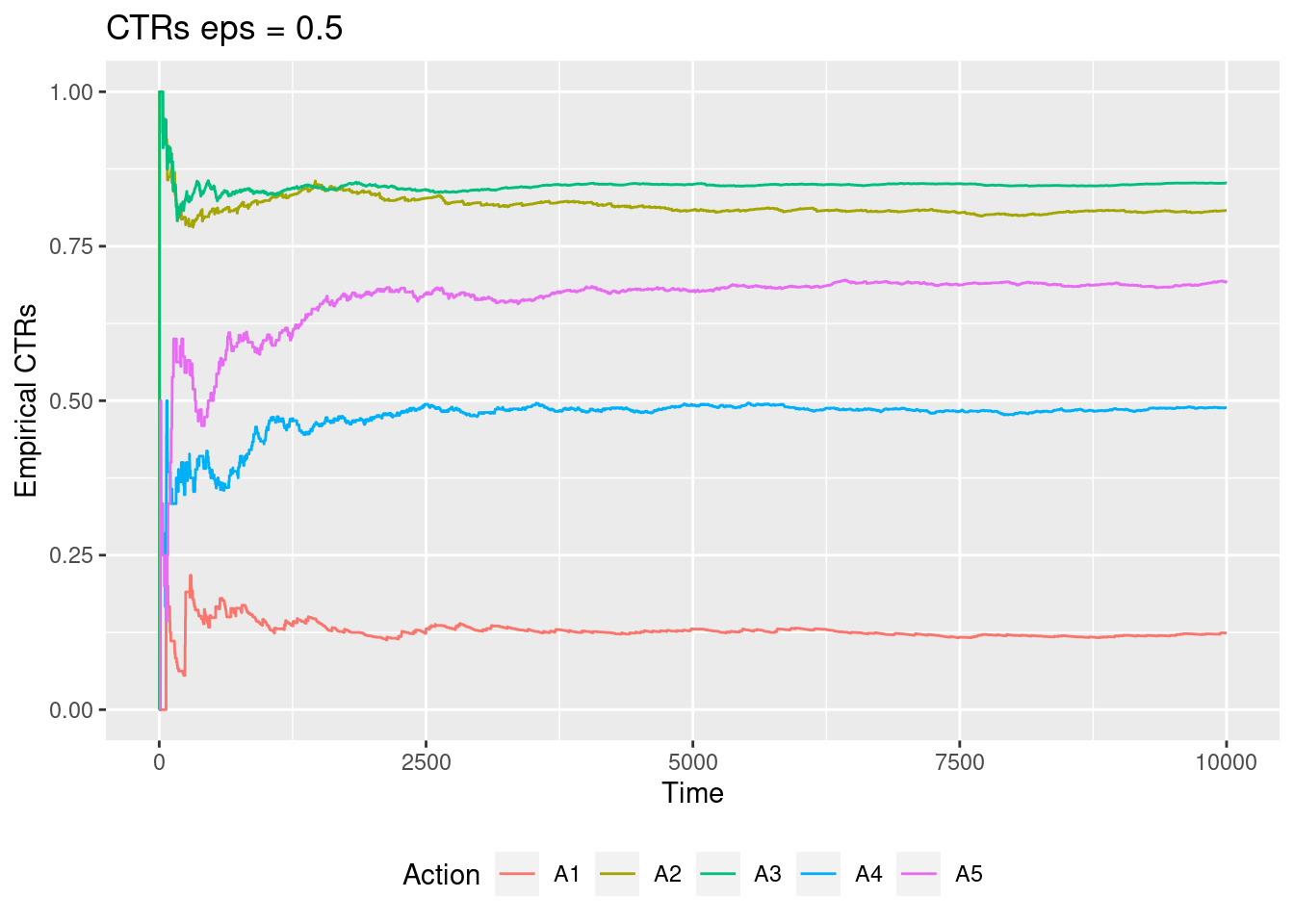
As epsilon grows we estimate the true values better for all actions.
- Make a plot of the empirical CTRs for \(\epsilon = 0.01, 0.5\) over 10000 time-steps, i.e. plot \(Q_t(a)\).
- Assume that the rewards of ad clicks is equal to (10, 8, 5, 15, 2). Modify the algorithm so you look at rewards instead of CTRs. What is the best action to choose?
We now modify the RLAgent and add an upper-confidence bound function selectActionUCB:
#' R6 Class representing the RL agent
RLAgent <- R6Class("RLAgent",
public = list(
#' @field qV Q estimates.
qV = NULL,
#' @field nV Action counter.
nV = NULL,
#' @field k Number of bandits.
k = NULL,
#' @field epsilon Epsilon used in epsilon greed action selection.
epsilon = NULL,
#' @description Create an object (when call new).
#' @param k Number of bandits.
#' @param epsilon Epsilon used in epsilon greed action selection.
#' @return The new object.
initialize = function(k = 10, epsilon = 0.01, ini = 0) {
self$epsilon <- epsilon
self$qV <- rep(ini, k)
self$nV <- rep(0, k)
self$k <- k
},
#' @description Clear learning.
#' @param eps Epsilon.
#' @return Action (index).
clearLearning = function() {
self$qV <- 0
self$nV <- 0
},
#' @description Select next action using an epsilon greedy strategy.
#' @return Action (index).
selectActionEG = function() {
if (runif(1) <= self$epsilon) { # explore
a <- sample(1:self$k, 1)
} else { # exploit
a <- which(self$qV == max(self$qV))
a <- a[sample(length(a), 1)]
}
return(a)
},
#' @description Select next action using UCB
#' @return Action (index).
selectActionUCB = function(c, t) {
val <- self$qV + c * sqrt(log(t + 0.01)/self$nV)
a <- which.max(val)
return(a)
},
#' @description Update learning values (including action counter).
#' @param a Action.
#' @param r Reward.
#' @return NULL (invisible)
updateQ = function(a, r) {
self$nV[a] <- self$nV[a] + 1
self$qV[a] <- self$qV[a] + 1/self$nV[a] * (r - self$qV[a])
return(invisible(NULL))
}
)
)- Test the UCB algorithm for \(c\) values \((0.1, 5, 10, 20)\). Which algorithm seems to find the best average reward?
2.9.2 Exercise - A coin game
Consider a game where you choose to flip one of two (possibly unfair) coins. You win 1 if your chosen coin shows heads and lose 1 if it shows tails.
- Model this as a K-armed bandit problem: define the action set.
- Is the reward a deterministic or stochastic function of your action?
- You do not know the coin flip probabilities. Instead, you are able to view 6 sample flips for each coin respectively: (T,H,H,T,T,T) and (H,T,H,H,H,T). Use the sample average formula (2.1) to compute the estimates of the value of each action.
- Decide on which coin to flip next assuming that you exploit.